
Has anyone tried to run Paper Machines? I have downloaded all the pre-req’s and I know it’s installed (my Firefox just updated and prompted me to review my add-ons – both Zotero and Paper Machines appeared in the list), but I don’t know how to initiate it in Zotero. The directions on GitHub are very sparse:
To begin, right-click (control-click for Mac) on the collection you wish to analyze and select “Extract Texts for Paper Machines.” Once the extraction process is complete, this right-click menu will offer several different processes that may be run on a collection, each with an accompanying visualization. Once these processes have been run, selecting “Export Output of Paper Machines…” will allow you to choose which visualizations to export.
When I right-click on a collection, no such option appears. This is what I see, even with all options investigated:
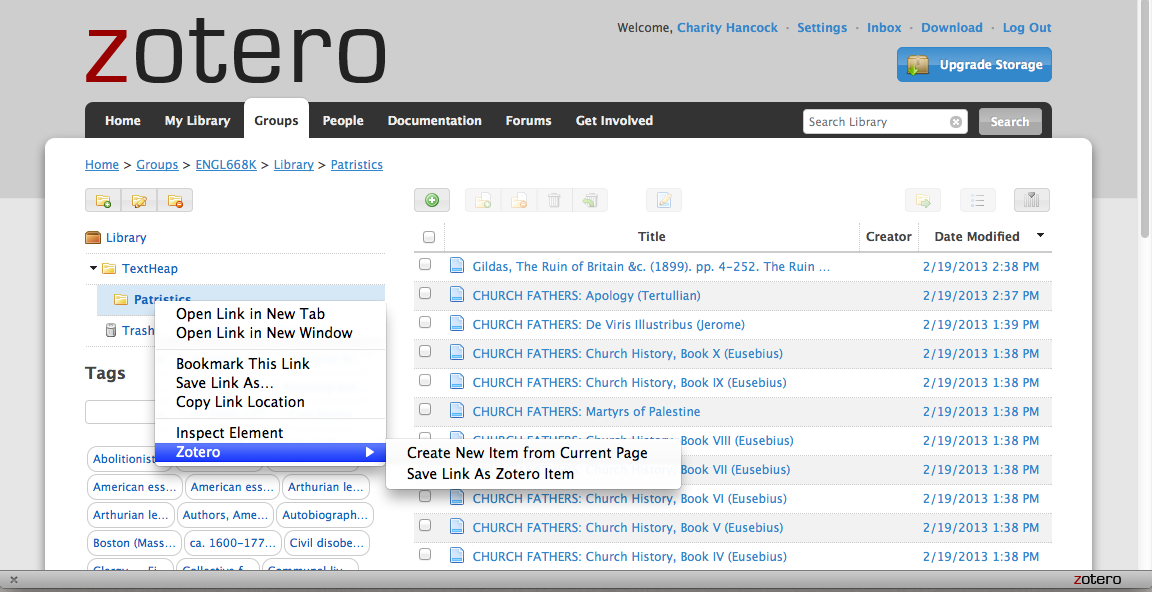
Anyone else have any success?
I encountered a problem as well. I ran the text extraction and then right-clicked on the group folder again to see several options (e.g. Word Cloud, Mapping, Topic Modeling) but they were all grayed out. In addition, the extraction process returned a “no log file found” error.
Will investigate to see what I (we?) could be doing wrong.
How did you even run a text-extraction? Am I missing something? How do you initiate Paper Machines – is there a button? A tab?
Charity,
I think you need to install the pdf indexing tool onto Zotero. Here are the instructions I followed:
Go to the Zotero’s preferences and click on the Search icon. If the pdf indexing is not installed, you can click on a button to install it.
After it’s installed, go to the Textheap collection and control click. Do you see the Paper Machines option in the little box that appears?
a corpus of documents with full text PDF/HTML and high-quality metadata (recommended: at least 1,000 for topic modeling purposes)
oops, I pushed “post” before I finished that reply. I also couldn’t get the extraction to work–I got the same log file message as Nigel.
Could you solve that? I am still trying, but nothing appears when I control click on the collection. I think there is something I am missing and I don’t understand what!
Did you follow Mary’s instructions after downloading Paper Machines? That solved my problems (I didn’t have the PDF indexing tool installed).
And I did it from the Zotero program, not the group webpage, if that’s any difference (I clicked on the icon on the bottom right corner of my browser to enlarge it, then followed Mary’s instructions).
THANK YOU, MARY! I got the same error message, “Extracting: TextHeap
The process log is displayed below. Refreshing status in 15 seconds.
No log file found,” but at least now I’m on par with everyone else. Whew.
I’m having problems as well. I installed the PDF indexing tool, but I don’t even see how to add items to the group collection. Are you guys using the standalone Zotero or the Firefox plugin?
I’m using the Firefox plugin. When you click on TextHeap, there will be a little green circle with a white plus on it – clicking that will take you to the add page (you can see the icon in my pic above, a little ways down from the Documentation tab).
Ok, that seems to be working. Thanks!
I did what Mary suggested and restarted firefox. Then right click on my collection and it worked! Thanks