Digitally Dissecting the Anatomy of “Frankenstein”: Part One
Posted by on Friday, February 24th, 2012 at 12:32 pm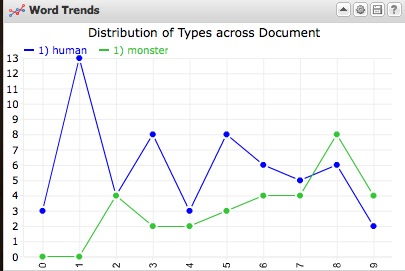
A frequency chart of the terms "human" and "monster" in Frankenstein.
A two-part blog post: the first post will cover grabbing and analyzing Twitter and other textual data and working with them in Wordle and TextVoyeur, and the second will use these tools to consider the function of body parts in Mary Shelley’s Frankenstein.
Get your data!
Text? If you’re producing a project you want other people to see, you’d want to locate–or scan/key-in yourself–a reliable edition of your text. For the purposes of this course, since I’m just asking a quick question for my own purposes, I’ll use the dubious (what edition? what errors?) Project Gutenberg etext I grabbed from this page. Don’t forget to remove the extra licensing information from the beginning and end!
Twitter? Finding old tweets from your individual account might not be difficult (especially if you don’t tweet hourly), but Twitter only saves hashtag searches for around ten days (there are some third-party sites such as Topsy that may have older tweets, but I’ve found these to be unreliable). The best policy is to start archiving once you know you’ve got a hashtag you’re interested in.
1. There are a bunch of ways to archive tweets, but I think the easiest if to set up an RSS feed through something like Google Reader. You can get the feed URL for any Twitter search by replacing “hashtag” in the following string with the search term of your choice (e.g. technoro):
https://search.twitter.com/search.atom?q\x3d%23hashtag
Once you set up your feed reader as subscribed to this URL, you’ll have a feed that updates with all new tweets using the hashtag. You can export these at any time you’d like to work with them in a visualization tool; place any feeds you want to export into a folder (visit Google Reader’s settings > Folders), then enter the following URL into your address bar (replacing “folder” with your folder name):
https://www.google.com/reader/public/subscriptions/user/-/label/folder
This will bring you to an XML file of your feed that you can save to your computer and edit.
2. Too much work? You can use a service like SearchHash, which will let you input a hashtag and download a CSV file (spreadsheet); this might be easier to work with if you’re unfamiliar with RSS feeds and/or XML, but you can only trust such services to cover about the last ten days of tweets.
Get out your tools!
1. Wordle is one of the fastest and easiest tools for checking out a text: you paste in your text or a link to a webpage, and it produces a word frequency cloud (the frequency with which a word appears in your text corresponds to how large the word appears in the cloud). Wordle lets you do a few simple things via the drop-down menu on the top of the visualization:
- remove stop-words (stop-words are words that appear frequently in texts but usually have little content associated with them–think things like articles and prepositions. If you’ve ever tried to make a word frequency cloud and seen some huge “THE” and “AN” type words, you need to filter your text with a stop-word list),
- change the look (color, font, orientation of text), and
- reduce the number of words shown (Wordle only shows the top x words appearing in a text).
Wordle is a simple way to get a look at the words being used in a text; you can get a quick sense of diction, preoccupations, and patterns. However, it doesn’t let you make any sort of strong argument beyond statements about what words are frequent; with text analysis, you always want to be able to “drill down” from your distant reading to the individual words or phrases or moments that make up the macro view you’re seeing, and Wordle doesn’t let you do that.
2. Luckily, there are free, web-based tools that let you go beyond Wordle’s abilities fairly easily. TextVoyeur* (aka Voyant) is really meant for comparing documents among a large corpus of texts, but you can use it to look at a few or even a single text. Voyeur maintains a great tutorial here that I recommend you visit to understand where different features are on the page, but here’s an overview of things you might want to do with it:
- A word frequency cloud (like Wordle), but with better stop-words. This cloud should appear in the upper-left corner; the settings button for each pane within the page appears when you click the small gear icon that appears in the upper-right of each pane, and clicking it in the cloud pane lets you turn on the stop-word list of your choice to filter out.
- A list of words in frequency order (click “words in the entire corpus” in the bar at the bottom-left; again, you can filter out stop-words). You can search in this pane for interesting words (e.g. “monster”); then, check the box next to the word, and in the pane that appears use the heart icon to add the word to the favorites list. You can add several terms to your favorites this way (e.g. monster, human, angel), then compare these favorites in the “word trends” pane, which with chart the frequency of these words’ appearances throughout your text.
- Drill down. “Keywords in context” lets you see where a given word appears in the novel. “Collocates” are words that tend to appear near other specific words. Collocation can help you understand a text’s rhetoric; is the word “monster” often near the word “abnormal” or “misunderstood”? TextVoyeur lets you set how near a given search term you want to look for collocates (e.g. one word on either side of your search term? fifteen words?). If you’re interested in a word with multiple meanings or that appears within larger words (e.g. the word count for “inhuman” may include the count for “human”; you might want to see whether “Frankenstein” is being used to refer to Victor or another family member), you might want to drill down into these examples and see how many of the examples feeding into the count actually support your argument.
3. The internet is full of free tools for working with texts, many with more specific foci (e.g. tools that attempt to determine the gender of a text’s author). Two places to start finding more tools:
- UCSB Toy Chest Toy Chest (Online or Downloadable Tools for Building Projects), especially the section on Text-Analysis Tools
- Project Bamboo’s DiRT (Digital Research Tools) Wiki, especially the “Analyze Text” page (old, easier to read version here)
- Python is a a great beginning programming language and plays nice with text. I’ll try to write a post on creating a Python script to filter out your own customized stop-word list from a text later this term (sometimes using find+replace is too onerous, but you want to remove a lot of non-stop-words like “#technoro” or “students”).
I’ll try to publish for the second part of this blog post later this week, where I’ll tackle a question about Frankenstein using some of these tools and also address some of these tools’ shortcomings (i.e. things you can’t say when pointing at these visualizations).
*Note that TextVoyeur was experiencing some interface issues today (2/24), which meant that we didn’t demo it at the DH Bootcamp. If you’re having trouble using this tool, those issues might not have been solved yet.
You can follow any responses to this entry through the RSS 2.0 You can leave a response, or trackback.
Pingback: Useful prosthetics, pretty metaphors? (and more on DH tools) - Technoromanticism
Pingback: Useful prosthetics, pretty metaphors? (and more on DH tools) « Literature Geek
Pingback: lustro piotrków
Pingback: Abrasives