About the Woodchipper: Byron and Austen
 This screenshot shows the prototype of a text visualization and analysis tool—code-named the Woodchipper—that we built at
CorporaCamp. The application allows users to build a selection of texts from across our three collections by searching for titles or author names
(we'll be adding full-text and faceted search soon).
A literary scholar might be interested in using the tool to look for
thematic patterns in several eighteenth-century epistolary novels, for example, while
a historian of medicine might wish to look at changing terminology in a body of Victorian publications on homeopathic practice.
The goal of the Woodchipper is to capture important aspects of the structure of collections
like these (which may contain hundreds of thousands—or even millions—of words) in a simple visual interface.
This screenshot shows the prototype of a text visualization and analysis tool—code-named the Woodchipper—that we built at
CorporaCamp. The application allows users to build a selection of texts from across our three collections by searching for titles or author names
(we'll be adding full-text and faceted search soon).
A literary scholar might be interested in using the tool to look for
thematic patterns in several eighteenth-century epistolary novels, for example, while
a historian of medicine might wish to look at changing terminology in a body of Victorian publications on homeopathic practice.
The goal of the Woodchipper is to capture important aspects of the structure of collections
like these (which may contain hundreds of thousands—or even millions—of words) in a simple visual interface.
Once the scholar has built the collection of texts that he or she is interested in, the application breaks each into smaller units for analysis and
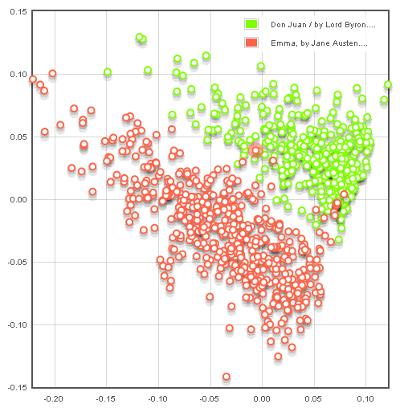
arranges these units in a two-dimensional map. The following image is a visualization produced for a collection of just two texts: Byron's
narrative poem Don Juan and Jane Austen's Emma:
In this example we're using pages as the units for analysis, since the electronic editions we have
for these two books are uncorrected and unstructured texts from the Hathi Trust. We use a technique called
topic modeling to characterize each page, and another technique called principal component analysis
to map these characterizations in two dimensions.
We can see from a glance at the map that the application has done a good job of distinguishing between the two texts,
since they form two fairly distinct clusters,
but on its own the map doesn't tell us much more than this.
We can add the component loadings to get a better sense of what's happening in this space.
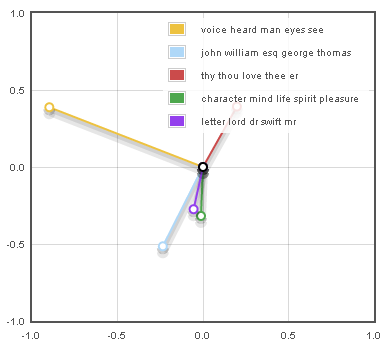
Each of the lines radiating from the center represents a topic from our topic model.
A "topic" in this sense is just a kind of weighted list of words that tend to occur together in certain patterns
in our corpus, and the key for this graph shows the five most prominent words for the topics that are most relevant in
this visualization. "voice heard man eyes see" is a kind of general narrative topic—these are words that are
often used together in descriptions of conversations or interactions between people.
We can see in the map that both Don Juan and Emma are "stretched" along this axis, with more narrative
passages appearing to the upper left, and more abstract passages to the lower right.
We can confirm this characterization by holding the mouse over individual points in the map, which will cause the text of the page to
be loaded in the panel on the right, as you can see in the first screenshot above. If we look at the pages toward the upper left-hand
corner of the map, we see that they tend to contain passages of quoted dialogue and descriptions of actions, while the pages to the
lower right tend to be more abstract descriptions of places or relationships.
We can also see another axis that is perpendicular to this one, with a topic consisting largely of first names pointing down and to the left,
and a topic characterized by more formal or archaic language pointing in the opposite direction.
If we return to the map, we see that the points of Byron's poem
lie in the more formal direction along this axis, while Austen's novel is more characterized by the use of first names.
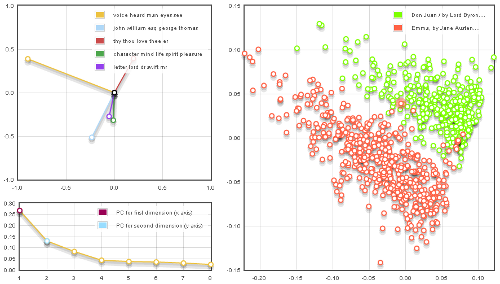
So far none of these observations are particularly remarkable or controversial: the map seems to do a reasonably good job of capturing
some basic characteristics of these works. It identifies the fact that both vary widely in term of narrative action (although Don Juan
is clearly more heavily weighted toward the "abstract" end of the spectrum than Emma here), and that one important distinguishing
characteristic is the diction and the use of first names.
We can "drill down" to explore other hypotheses that we might have about these two texts.
We might expect, for example, that the pages from Don Juan that cluster most
closely with Emma would tend to be from the later cantos, in which Juan visits
England. This is in fact the case: if we look at a few dozen of the green points that are closest to the red cluster,
we find that a large majority of them are from Cantos XIV, XV, and XVI.
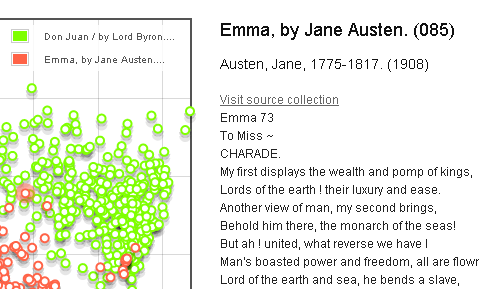
In the image above we see that the map positions the verse charade scene in Chapter 9 of Emma in Don Juan's thematic space.
The question of Byronic echoes or influence in Austen's fiction could be debated at length, of course,
but these passages certainly aren't an unreasonable choice for the most "Byronic" in this novel.
Continued exploration of the map might invite us to form new hypotheses, which should then lead us back to the texts for closer analysis.
At a glance, for example, it appears that Emma becomes increasingly characterized by narrative action as the story progresses,
while Don Juan moves along the other axis: from more formal or stylized language to less. The outliers are also interesting:
in the upper right corner, for example, is this page
of Don Juan, which includes two stanzas that are arguably among the most fancifully digressive in the poem.
Woodchipper was built primarily to inform the Corpora Space design process:
preparing for and carrying out CorporaCamp has given us insight into the
problems and challenges we face in designing Corpora Space.
We also hope, however, that this simple visualization tool that we've built might serve as an example
of one way that scholars can explore and interact with very large text collections, and that the work
that we've started in this three-day code sprint might lead to more sophisticated visualizations and interfaces. If you're interested in trying out the Woodchipper
on your own selection of texts, please sign up for the alpha test, and let us know if you have questions
or comments about the approaches we've described here, or about the role that the Woodchipper has played in our design process.